As part of our Data Upgrade from AX 2012 to Dynamics 365 Finance and Operations we had to ensure a way of telling how many records do we have per data area. Data import via entities are company-based, so we had to find out a reliable way to tell if everything has been successfully transferred. The following script can tell exactly that, show the SQL record count by company:
SET NOCOUNT ON
DECLARE @tableName NVARCHAR(255);
DECLARE @statement NVARCHAR(MAX);
-- Temporary table for storing record counts
CREATE TABLE #jdm_count (TableName NVARCHAR(255), Company NVARCHAR(4), RecordCount int)
-- Cursor for getting list of User-created tables
DECLARE cur_name CURSOR FOR
SELECT QUOTENAME(SCHEMA_NAME(sOBJ.schema_id))
+ '.' + QUOTENAME(sOBJ.name)
FROM sys.objects as sOBJ
WHERE
sOBJ.type = 'U'
AND sOBJ.is_ms_shipped = 0x0
ORDER BY SCHEMA_NAME(sOBJ.schema_id), sOBJ.name;
OPEN cur_name
-- Loop tables
FETCH NEXT FROM cur_name INTO @tableName
WHILE @@FETCH_STATUS = 0
BEGIN
-- Construct SQL Statement for getting company-specific record count
SELECT @statement = 'SELECT ''' + @tableName + ''' AS [TableName]'
+ IIF(COL_LENGTH(@tableName, 'DATAAREAID') IS NOT NULL, ', DATAAREAID AS [Company]', ', '''' AS [COMPANY]')
+ ',COUNT(*) AS [RowCount] FROM ' + @tableName + ' WITH (NOLOCK)'
+ IIF(COL_LENGTH(@tableName, 'DATAAREAID') IS NOT NULL, ' GROUP BY [DATAAREAID]', '')
+ ' HAVING COUNT(*) > 0';
-- Insert statement results in temporary table
INSERT INTO #jdm_count (TableName, Company, RecordCount)
EXEC sp_executeSQL @statement;
FETCH NEXT FROM cur_name INTO @tableName
END
CLOSE cur_name
DEALLOCATE cur_name
-- Display results
SELECT * FROM #jdm_count
ORDER BY RecordCount DESC, TableName, Company
DROP TABLE #jdm_count
SET NOCOUNT OFF
When we have decided to use a Data migration instead of a Data upgrade to D365FO we had to come up with a way to identify tables to migrate.
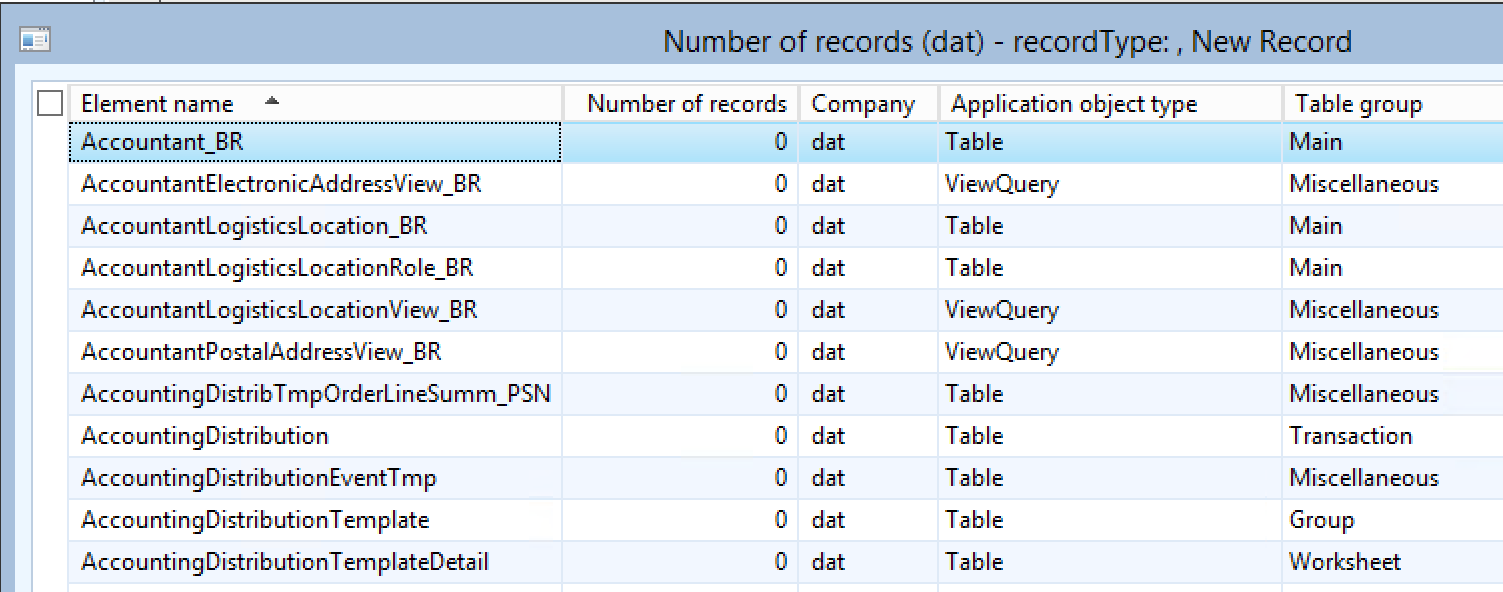
The AX developer client already has a form under Tools > Number of records, which can tell you how many rows does a table have. This form can be easily expanded to include additional information. The most useful are the table type, and the application layer.
You would typically want to migrate all tables which belong to the following Table groups:
Parameters
Group
Main
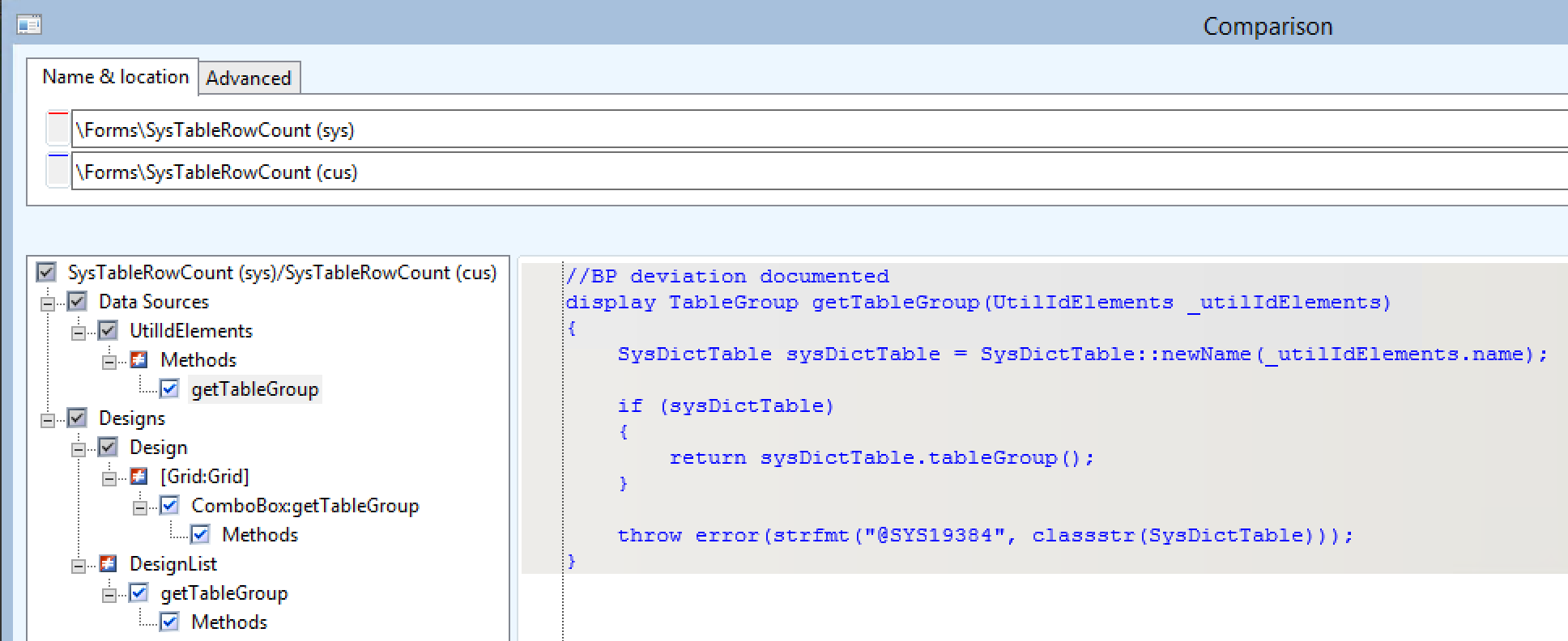
This is how you can add the table type display method and control to the SysTableRowCount form to identify tables to migrate:
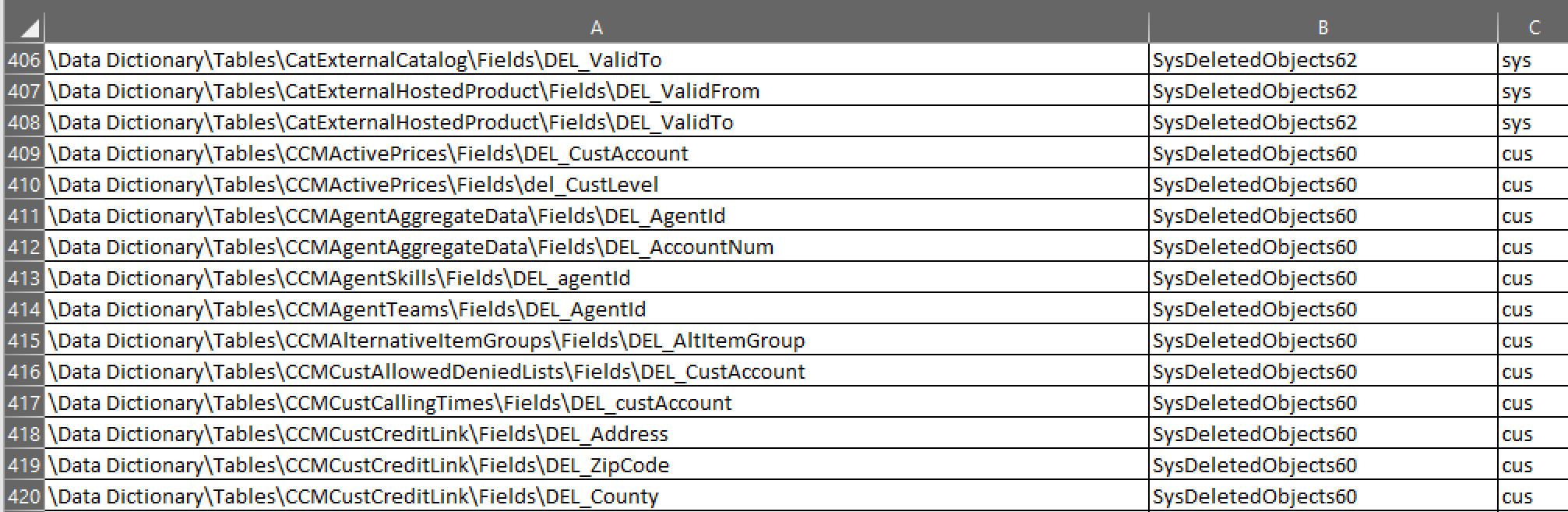
During our code upgrade we have identified that the SysDeletedObjects configuration keys were still turned on. Also many DEL_-prefixed fields were being referred or used in various places. We had to come up with a way for finding objects marked for deletion.
The documentation gives you an idea of what to do with such elements.
As part of our code upgrade to Dynamics 365 Finance and Operations we have removed some processes, for which the security roles had to be refreshed en mass. For this I have decided to go with modifying D365FO metadata using reflection to see how can we do it with the new file-based repository.
First I have created a new C# project and referred the following 3 Dynamic Link Libraries from the AOSService\PAckagesLocal\bin folder:
Then the following code was developed, which shows how to manipulate the metadata using the new DiskMetadataProvider classes. In the example below we were working against the JADOperation package and AxSecurityRole objects.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.Dynamics.AX.Metadata.Storage;
using Microsoft.Dynamics.AX.Metadata.Core.Collections;
using Microsoft.Dynamics.AX.Metadata.Providers;
using Microsoft.Dynamics.AX.Metadata.MetaModel;
namespace ModifyAOT
{
class Program
{
static bool removeNode(
AxSecurityRole _role,
KeyedObjectCollection<AxSecurityPrivilegeReference> _privs,
string _node
)
{
bool isModified = false;
if (_privs.Contains(_node))
{
Console.WriteLine("Removing " + _role.Name + "." + _node);
_privs.Remove(_node);
isModified = true;
}
return isModified;
}
static void Main(string[] args)
{
string packagesLocalDirectory = @"C:\AosService\PackagesLocalDirectory";
IMetadataProvider diskMetadataProvider = new MetadataProviderFactory().CreateDiskProvider(packagesLocalDirectory);
var l = diskMetadataProvider.SecurityRoles.ListObjects("JADOperation");
var le = l.GetEnumerator();
while (le.MoveNext())
{
bool isModified = false;
AxSecurityRole r = diskMetadataProvider.SecurityRoles.Read(le.Current);
KeyedObjectCollection<AxSecurityPrivilegeReference> privs = r.Privileges;
isModified = removeNode(r, privs, "JADCCDelayCaptureBatchProcess") || isModified;
isModified = removeNode(r, privs, "ProfitAccountStatistics_CustItemGenerate") || isModified;
isModified = removeNode(r, privs, "CCMOrderPadLoginManagementMaintain") || isModified;
if (isModified)
{
ModelSaveInfo model = diskMetadataProvider.ModelManifest.ConstructSaveInfo(diskMetadataProvider.ModelManifest.GetMetadataReferenceFromObject("JADOperation", "AxSecurityRole", r.Name).ModelReference);
diskMetadataProvider.SecurityRoles.Update(r, model);
}
}
Console.WriteLine("Press any key to continue...");
Console.ReadKey();
}
}
}
And this is all that you require for modifying D365FO metadata using reflection.
You can find some other use cases of doing metadata reflection in previous blog posts as well:
The Document Attachments were stored in our AX 2012 database, and were occupying several hundred GBs. As part of the migration to D365FO we had to export these files in bulk. The most efficient way is to run the batch task in parallel. But this data is tilted in a way that if you would group the tasks based on their creation date, it the first tasks would barely have any records to process while the last ones would go on forever. The solution for this is called data histogram equalization.
It would be a big challenge to code this in X++, but SQL Server has a function for doing this exactly: NTILE.
The following direct query is able to process the data histogram, and then return 10 buckets of Record Identifier ranges of roughly equal size:
WITH documents (Bucket, RecId)
AS (
SELECT NTILE(10) OVER( ORDER BY DocuRef.RecId) AS Bucket
,DocuRef.RECID
FROM docuRef
INNER JOIN docuType
ON (docuType.dataAreaId = docuRef.RefCompanyId OR DOCUREF.REFCOMPANYID = '')
AND docuType.TypeId = docuRef.TypeId
INNER JOIN docuValue
ON docuValue.RecId = docuRef.ValueRecId
WHERE docuType.TypeGroup = 1 -- DocuTypeGroup::File
AND docuType.FilePlace = 0 -- DocuFilePlace::Archive
AND docuType.ArchivePath <> ''
AND docuValue.Path = ''
)
SELECT Bucket
,count(*) AS Count
,(SELECT MIN(RecId) FROM documents D WHERE D.Bucket = documents.Bucket) AS RecId_From
,(SELECT MAX(RecId) FROM documents D WHERE D.Bucket = documents.Bucket) AS RecId_To
FROM documents
GROUP BY Bucket
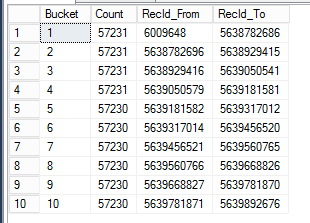
Here are the results for spawning 10 batch job tasks to do parallel execution based on the RecId surrogate key index, with ~57230 rows in each bucket. This allows you to evenly distribute the load for data processing in parallel.
If we would export our document attachments sequentially, it would take roughly 40 hours total. By utilizing the data histogram equalization we could get it down to be under 3 hours. That is amazing!
It is a great way to split ranges of data for parallel processing, to keep in mind for the future.